Graph Representation Learning Strategies for Omics Data: A Case Study on Parkinson’s Disease
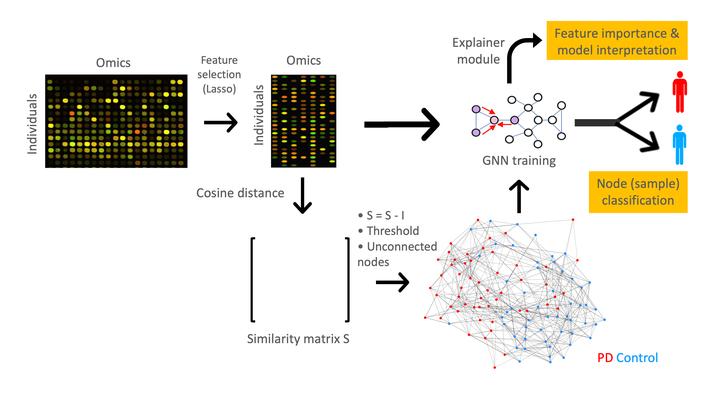 Image credit: From Gomez de Lope E et al.
Image credit: From Gomez de Lope E et al.
Abstract
Omics data analysis is crucial for studying complex diseases, but its high dimensionality and heterogeneity challenge classical statistical and machine learning methods. Graph neural networks have emerged as promising alternatives, yet the optimal strategies for their design and optimization in real-world biomedical challenges remain unclear. This study evaluates various graph representation learning models for case-control classification using high-throughput biological data from Parkinson’s disease and control samples. We compare topologies derived from sample similarity networks and molecular interaction networks, including protein-protein and metabolite-metabolite interactions (PPI, MMI). Graph Convolutional Network (GCNs), Chebyshev spectral graph convolution (ChebyNet), and Graph Attention Network (GAT), are evaluated alongside advanced architectures like graph transformers, the graph U-net, and simpler models like multilayer perceptron (MLP). These models are systematically applied to transcriptomics and metabolomics data independently. Our comparative analysis highlights the benefits and limitations of various architectures in extracting patterns from omics data, paving the way for more accurate and interpretable models in biomedical research.
Elisa G. de Lope
Bioinformatician in ML
My research interests include statistics, data mining, -omics, and drug discovery.